Identity Solutions – Determinisztikus vs. probabilisztikus modell
A sikeres marketinghez minden potenciális vásárló alapos megértése szükséges. A marketingszakemberek több különböző forrásból gyűjtik az ehhez elengedhetetlen információkat – közösségi média interakciók, e-kereskedelem, értékesítési pontok és bolti értékesítések, ügyfélszolgálati ügyek, emailek és szöveges üzenetek, és sok más egyéb által. Az ezekből az adatforrásokból származó adatok összessége átfogó képet nyújt a potenciális ügyfelekről.
Az identity resolution folyamata azt jelenti, hogy ezekből a különböző adatforrásokból származó adatokat egyetlen adatbázisba összesítik. Ennek eredménye egy egységes, 360 fokos nézet minden vásárlóról.
A determinisztikus és probabilisztikus személyazonossági adatok a digitális hirdetési körök új hívószavaivá váltak. Ezeket a kifejezéseket már évek óta ismerik a digitális hirdetők, kiadók és hirdetéstechnológiai vezetők. Azonban most, hogy az egész iparág a third-party cookie alternatíváját keresi, úgy tűnik, hogy gyakrabban felmerülnek, különösen az úgynevezett cookie-mentes azonosítók esetében.
Mit jelent a determinisztikus és probabilisztikus adat?
A determinisztikus adatok olyan információk, amelyekről köztudott, hogy igazak és pontosak, mivel közvetlenül emberek szolgáltatták vagy személyesen azonosíthatóak, például nevek vagy email címek. Gyakran hitelesített adatoknak is nevezzük őket.
A probabilisztikus adatok valószínűségeken alapszanak. Egyedi információkból állnak, mint például az eszköz operációs rendszere vagy IP-címe és ezeket egymással összeállítva az algoritmus egy következtetést von le. Az ad tech esetében a valószínűségi adatok használhatóak azonosítók létrehozásában.
Determinisztikus modell
Ez a típus elsősorban first-party adatokat használ és pontos egyezésekre támaszkodik. Változtathatatlan vagy állandó információkat vesz alapul, mint például a név, az otthoni és email cím, születési dátum, telefonszám vagy útlevélszám, és ezeket felelteti meg két vagy több ügyfélrekord során.
Mivel olyan adatokra támaszkodik, amelyek általában állandóak maradnak – például valakinek a neve -, a determinisztikus modellek pontosabbnak számítanak. Azonban statikus adatokat tartalmazó rekordokra korlátozódnak, ezáltal pedig figyelmen kívül hagyják az érvényes egyezéseket pontatlan adatok, például egy félreírt név miatt. Vagyis esetében az összeegyeztethető rekordok köre korlátozottabbnak bizonyul.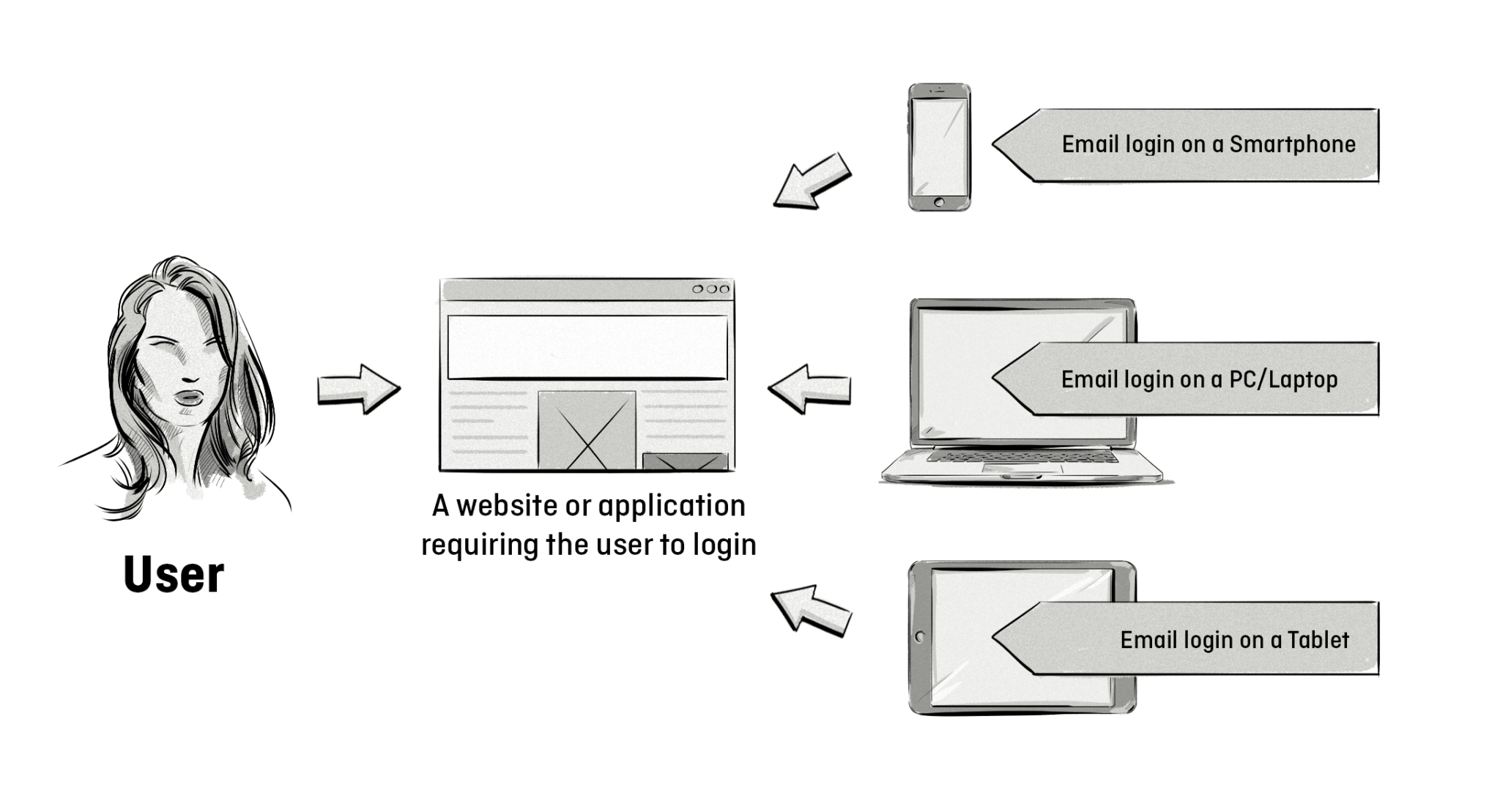
A determinisztikus modell előnyei
A determinisztikus egyeztetés 70-80%-os pontosságot eredményez, amely annak köszönhető, hogy ismert azonosítókra, például email címekre és munkakörökre támaszkodik. A benne rejlő pontosság pedig számos előnnyel jár:
- Javítja az ügyféladatbázis minőségét és lehetővé teszi, hogy személyre szabhatóak legyenek az email és eszközspecifikus in-app üzenetek. Intuitívabb ügyfélutakat hoz létre olyan részletes kritériumok alapján, mint például a korábbi termékvásárlások.
- A modell alapján létrehozott adatbázisok tartósabbak, hiszen az új információk hozzáadása mellett fenntartja az egyezéseket a meglévő rekordok között, miközben az új adatokat könnyedén egyezteti a régebbi adatokkal.
- Lehetővé teszi, hogy az egyeztetés szabályait meghatározzuk.
- Az adatok harmadik féltől származó forrásokkal is könnyen ellenőrizhetőek, ezáltal is tovább javítva a pontosságot.
- Ezen túlmenően a kapcsolataik könnyen érthetőek és követhetőek az emberek számára, mivel az algoritmusok egyszerűek és könnyűszerrel azonosítható adatokat vesznek alapul.
A determinisztikus modell hátrányai
Mivel több tényezőt használ egy azonosító meghatározásához, a determinisztikus egyeztetés nem tud pontos identitásgráfot felépíteni, ha akár egy tényező is hiányzik az adott rekordból. Akkor is nehézséget okoz a gráf felépítése, ha a két rekord elírás miatt különbözik egymástól.
A determinisztikus modell típusai
A determinisztikus identity resolution eszközök három fő módszerrel működnek:
- A single-field matching csak egy változót vagy egyedi azonosítót (pl. email címet) alkalmaz annak eldöntésére, hogy a két rekord ugyanarra a felhasználóra vonatkozik-e.
- A composite-field matching két vagy több azonosítót hasonlít össze annak érdekében, hogy eldöntse a két rekord ugyanarra a személyre vonatkozik.
- A cascading determinisztikus heurisztikus matching hasonló elven működik, mint a composite-field matching, ugyanakkor szabályai tartalmaznak már ha/akkor forgatókönyveket is. Például, ha két rekord email címe és vezetékneve nem egyezik pontosan, akkor azt vizsgálja tovább, hogy az email cím és a vezetéknév első négy betűje egyezik-e. Ezáltal akkor is képes egyezést azonosítani, ha bizonyos változók inkonzisztensek. A több változó használata pedig csökkenti a hamis pozitívok és hamis negatívok előfordulását.
Hogyan használható a determinisztikus adat az azonosító létrehozásában?
A determinisztikus azonosító akkor határozható meg, ha egy kiadó vagy hirdető által szolgáltatott email címet a felhasználók identitásgráfján vagy adatbázisában ugyanazzal az email címmel egyeztetik. Vagy például determinisztikus egyeztetés történhet, ha két entitás felismer egy azonosítót és pontosan egyeztetni tudja azokat egymással. Bizonyos esetekben három determinisztikus adat használható a szükséges pontok összekapcsolásához. Ha például ismert, hogy az ID1234 a johndoe@johndoe.com email címhez tartozik és tudjuk, hogy a johndoe@johndoe.com email cím az ID6789 azonosítóhoz tartozik egy másik adatbázisban, akkor a két azonosító determinisztikusan egyezik egymással.
Probabilisztikus modell
Ez a típusú egyeztetés olyan algoritmusokat használ, amelynek segítségével megjósolja az egyezéseket több hasonló adatrekord között. A statikus információk mellett olyan viselkedési adatokat is figyelembe vesz, mint például a felhasználói út és eszközhasználat. Az algoritmusok tehát megalapozott találgatásokat tesznek annak valószínűségére vonatkozóan, hogy az adatok egy potenciális ügyfélhez kapcsolódnak-e.
Bár kockázatosabb lehet, mint a determinisztikus modell, a probabilisztikus egyeztetés kevésbé nyilvánvaló összefüggéseket is feltárhat, mivel az algoritmusok szélesebb adathalmazt képesek elemezni, illetve figyelembe veszik a helytelen és hiányzó adatokat is.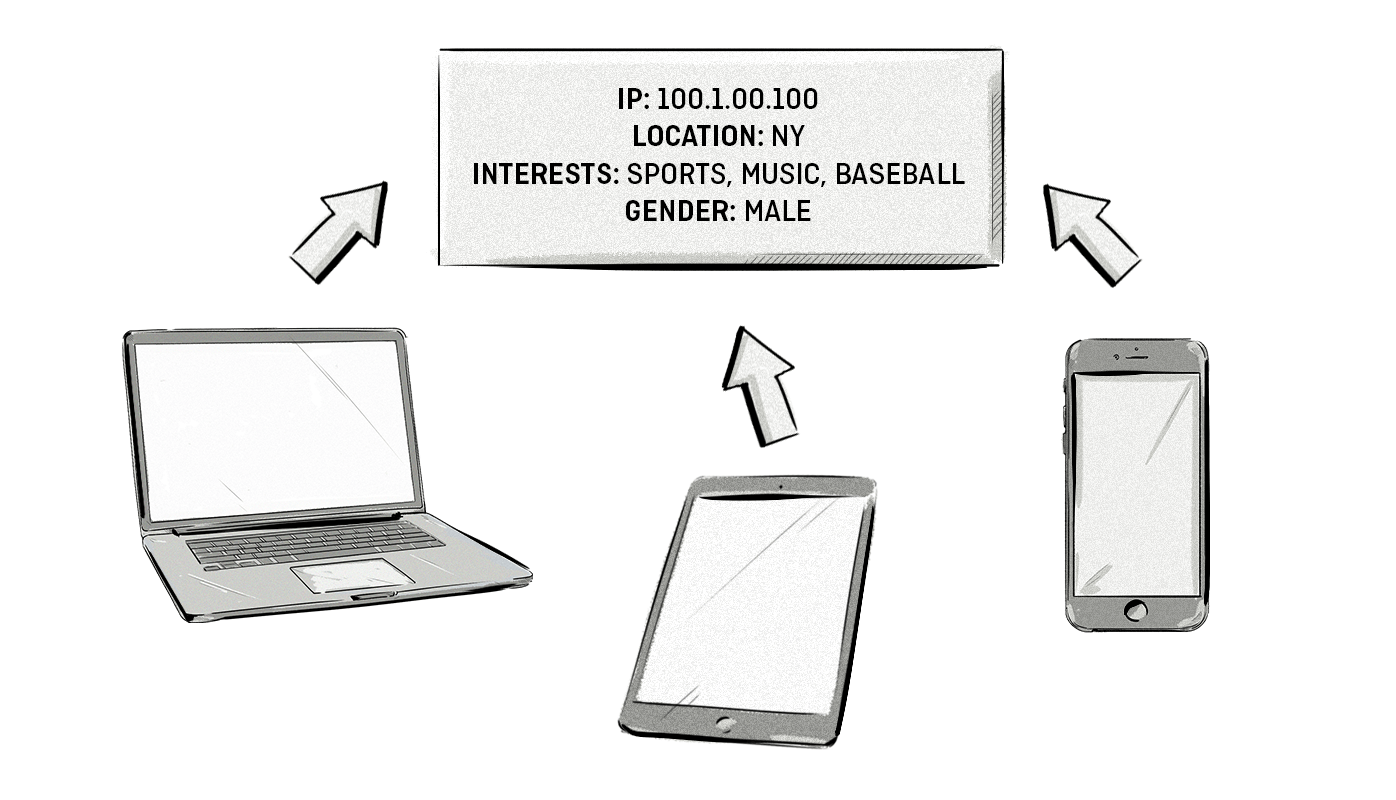
A probabilisztikus modell előnyei
A probabilisztikus modell olyan információkat értékelhet, mint például az IP-címek, operációs rendszerek, valós idejű földrajzi hely és hálózat. Felmérheti a felhasználó viselkedésével kapcsolatos adatokat, például korábbi vásárlásokat vagy letöltött tartalmakat. Ez egyúttal azt is jelentheti, hogy létrehozhat felhasználói profilokat anélkül, hogy személyes adatokat gyűjtene, amelyekre általában adatvédelmi előírások vagy iparági szabályozások vonatkoznak.
Míg a determinisztikus modell javítja az adatbázis minőségét, a probabilisztikus modell növeli az adatbázis méretét és ezáltal több lehetőséget kínál a marketingkampányok számára.
Javítja a tartalommarketing minőségét, illetve lehetővé teszi, hogy valós időben aktuális érdeklődési körök alapján targetálja a felhasználókat.
Képes megjósolni, hogy a vásárlók miképpen fognak viselkedni a jövőben, például lehetővé téve, hogy a vásárlási útjuk során hamarabb eljuttassuk hozzájuk a termékeket, mint a konkurencia.
A probabilisztikus modell hátrányai
A probabilisztikus modell algoritmusai kevésbé pontosak, mint a determinisztikus modell esetében, mivel találgatják a különböző adatforrások közötti kapcsolatokat.
A modell viselkedéssel és preferenciákkal kapcsolatos adatokat is tartalmaz, amely azt is eredményezheti, hogy ezek változásával az egyezések idővel kevésbé pontossá vagy irrelevánssá válhatnak.
Illetve az algoritmusnak nehezére eshet különbséget tenni a termék megvásárlása iránt érdeklődő és a termékről pusztán kutatást végző személy között. Tehát a feltételezett kapcsolatai nem mindig relevánsak és hamis pozitívot eredményezhet.
Ezenkívül az új adatvédelmi előírások és a third-party cookie-k megszűnése nehezíti a probabilisztikus modell számára szükséges harmadik féltől származó adatok gyűjtését, ennek köszönhetően pedig az algoritmus pontossága az adatpontok csökkenésével párhuzamosan csökken.
A pontatlan ügyfélprofilok további nehézségeket okozhatnak:
- Veszélyezteti az ügyfélélményt azáltal, hogy bizonyítja a felhasználónak, hogy a márka félreérti a célközönségét és irreleváns üzeneteket továbbít a számukra.
- Növelheti a reklám- és marketingkampányok költségeit, hiszen vagy kevésbé releváns célközönséget targetáltak, vagy teljesen elmulasztották azt.
- Manuális beavatkozásra lehet szükség annak érdekében, hogy az adatbázis pontos legyen és maradjon a jövőben.
- A probabilisztikus modell alkalmazása során nehezebb az új adatokat és a meglévő rekordok párosítása, ezáltal is tovább csökkentve a pontosságát.
A probabilisztikus modell típusai
A modell algoritmusai különféle technikákat alkalmaznak.
- A fuzzy string matching oly módon azonosítja az egyezéseket, hogy növeli a két adat közötti eltérések tűréshatárát. Azok a keresőmotorok, amelyek kitalálják a hibásan írt szavak helyes írásmódját szintén ezt a modell típust használják.
- Az advanced machine learning matching egy AI-vezérelt keresési kategória, amely magába foglalja a szavak és fogalmak kapcsolatának értékelését, neurális egyezéseket (felméri a lekérdezések és a weboldalak közötti kapcsolatot a kulcsszavak helyett).
- A cascading vegyes heurisztikus matching különböző determinisztikus és probabilisztikus algoritmusokat alkalmaz a legszigorúbbtól a legkevésbé szigorúig haladva. Ez lehetővé teszi az eszköz számára, hogy a kritériumok „kaszkádja” alapján határozza meg az egyezéseket. A modell csökkenti a hamis pozitív és a hamis negatív értékeket.
- A phonetic matching egyszerű keresőtáblázatokat vagy machine learning algoritmust használ az egyezés meghatározására, ha két szó egyformán hangzik, de másképp írják őket.
Választás a determinisztikus és probabilisztikus modell között
A determinisztikus modell a gyakorlatban
A determinisztikusan egyeztetett adatok pontossága alkalmassá teszi a használatát olyan kampányok során, amelynél kiemelten fontos a személyre szabott ügyfélélmény, vagy a célcsoport részletes szegmentálása. Például a széles termékválasztékkal rendelkező márkák, mint például a sminktermékeket értékesítő cégek determinisztikus adatokat használnak arra, hogy bizonyos felhasználókat meghatározott termékekkel targetáljanak.
Illetve arra is ideális, hogy kizárólag leendő, potenciális vásárlókat célozzanak meg, például egy adott mobiltelefon tulajdonosának vagy egy adott kábeltelevíziós csomag előfizetőjének releváns frissítéssel.
Determinisztikus adatokat alkalmaz például az Unified ID 2.0, ConnectID és a CORE ID.
A probabilisztikus modell a gyakorlatban
A probabilisztikus modell által generált hamis pozitív eredmények néha hasznosak is lehetnek. Például egy csúcskategóriás vagy luxuscikk esetében a célközönség túl tág meghatározása növelheti a márka ismertségét olyan vásárlók körében is, akik valószínűleg nem érdekeltek a vásárlásban. A különböző szervezetek gyakran hasonló okokból használnak probabilisztikus modelleket a digitális hirdetések elhelyezésénél és a tartalom összehangolásánál.
A probabilisztikus adatok ideálisak arra is, hogy a potenciális vásárlókat az ügyfélút minden szakaszában egyidejűleg érjék el, ezt a taktikát gyakran alkalmazzák az autós vagy B2C szoftvercégek.
Probabilisztikus adatokat alkalmaz például az Ekata.
Az identity resolution és a marketing
A különböző szervezetek determinisztikus és probabilisztikus modelleket is használhatnak marketingadatok gyűjtésére. Például a legtöbb vásárló egynél több eszközt használ ugyanazon webhely böngészéséhez. A determinisztikus modell ilyen esetben segíthet megérteni, hogy melyik marketingcsatorna eredményezi a legtöbb konverziót.
A probabilisztikus modell információt nyújthat olyan kérdésekben, hogy például mely kampányok milyen vásárlókkal fognak rezonálni, mely vásárlókat fenyegeti a lemorzsolódás veszélye, mikor váltak a marketingút során a potenciális vásárlókból tényleges vásárlók, milyen taktika eredményezte a legtöbb eladást vagy éppen milyen ügyfelek váltak el a márkától.
A következő cikkünkben a Prebid User ID alkalmazhatóságával fogunk foglalkozni.
Forrás:
https://digiday.com/media/wtf-is-the-difference-between-deterministic-and-probabilistic-identity-data/
https://www.growthloop.com/university/article/deterministic-vs-probabilistic-matching
https://clearcode.cc/blog/deterministic-probabilistic-matching/
